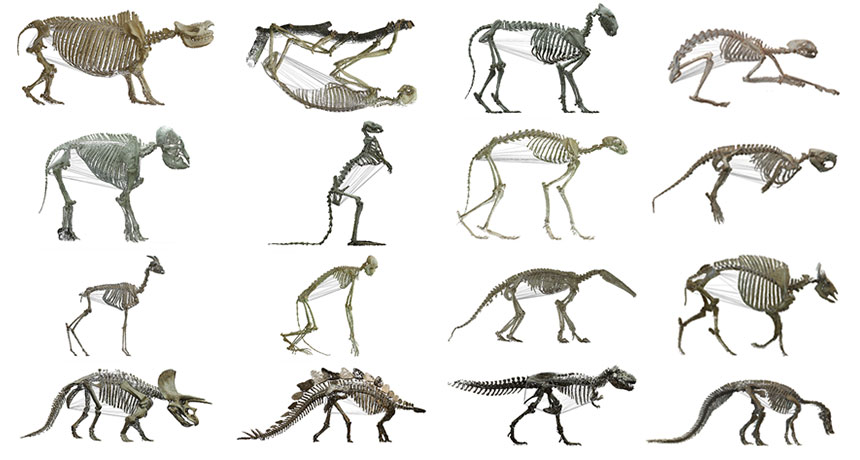
These skeletons are spilling their guts about the size of the body cavity that housed these animals’ stomach and intestines.
Using digital 3-D scans of mounted skeletons, researchers estimated the body cavity volume in 126 species. Of the 76 mammal species, plant eaters had bigger bellies; their relative torso volumes were about 1.5 times as large as those of carnivores, researchers report online November 4 in the Journal of Anatomy.
The study is the first to quantitatively test the long-held idea that herbivores have bigger torsos, says Marcus Clauss of the University of Zurich. Plant eaters are thought to need extra space for complex systems that digest a leafy diet. Surprisingly, Clauss and colleagues didn’t find the same pattern in nonavian dinosaurs, birds or reptiles, but the researchers had fewer skeletons to compare. Of the 27 dinosaurs, for example, only four were carnivores.
Still, the research suggests that in tetrapods — four-limbed vertebrates — only mammalian herbivores have larger body cavities, raising questions about why that might be evolutionarily. “Everybody goes crazy about the long neck or the strange things” on an animal’s head, Clauss says. But few scientists have focused on the torso’s frame and how diet helps sculpt it over time. “This study emphasizes that the torso is an important part of overall body shape.”
SAN DIEGO — Society’s record for protecting public health has been pretty good in the developed world, not so much in developing countries. That disparity has long been recognized.
But there’s another disparity in society’s approach to public health — the divide between attention to traditional diseases and the resources devoted to mental disorders.
“When it comes to mental health, all countries are developing countries,” says Shekhar Saxena, director of the World Health Organization’s department of Mental Health and Substance Abuse. Despite a breadth of scope and depth of impact exceeding that of many more highly publicized diseases, mental illness has long been regarded as a second-class medical concern. And modern medicine’s success at diagnosing, treating and curing many other diseases has not been duplicated for major mental disorders.
Saxena thinks that neuroscience research can help. He sees an opportunity for progress through increased interdisciplinary collaboration between neuroscience and mental health researchers.
“The collaboration seems to be improving, but much more is needed and not only in a few countries, but all countries,” he said November 12 at the annual meeting of the Society for Neuroscience.
By almost any measure, mental health disorders impose an enormous societal burden. Worldwide, direct and indirect costs of mental disorders exceed $2.5 trillion yearly, Saxena said — projected to reach $6 trillion by 2030. Mental illnesses also disable and kill in large numbers: Global suicides per year total over 800,000. “Indeed, it is a hidden epidemic,” Saxena said. That’s more deaths than from breast cancer and probably more from malaria, according to a new comprehensive analysis of global mortality.
Mental illnesses encompass a wide range of disorders, from autism and Alzheimer’s disease to substance abuse and schizophrenia. Saxena acknowledged that there have been advances in the scientific understanding of these diseases, but not nearly enough. No easily used diagnostic test is available for most of them. And no new class of drugs for treating major mental disorders has appeared in the last 20 years, with the possible exception of dementia.
“We need increased investment in research, increased public, private and philanthropic investments,” Saxena said. “We need increased connection of research with public health gains.” He called on the community of neuroscientists to establish a “grand challenge” to researchers to address these concerns.
“There have been many grand challenges in neurosciences — perhaps we need one for finding out mental health interventions,” he said.
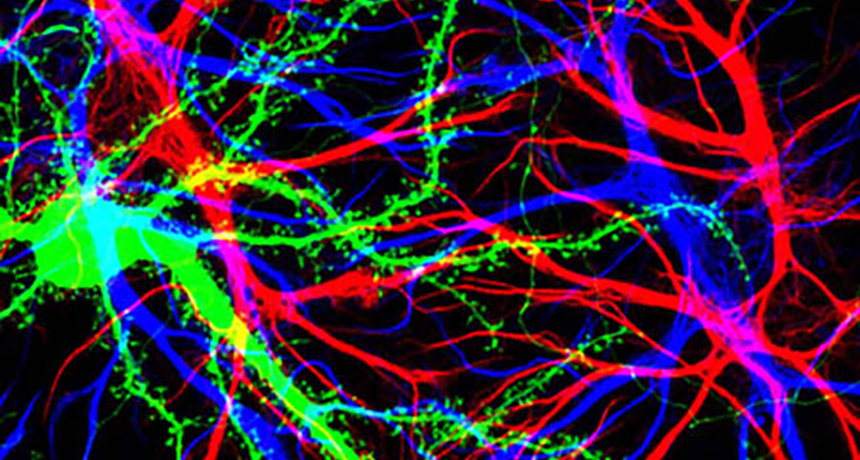
Many neuroscientists are, of course, aware of the important link between their research and mental health. Some progress is being made. One promising avenue of work focuses on synapses, the junctures through which nerve cells in the brain communicate. Typically synapses form where axons, the long neuronal extensions that transmit signals, connect with dendrites, the neurons’ message-receiving branches. Most of the axon-dendrite connections occur at small growths called dendritic spines that protrude from the dendrite surface.
Several sessions at the neuroscience meeting described new work showing ways in which dendritic spines may be involved in mental disorders. One session focused on the protein actin, a prime structural component of the spines.
Actin activity depends on a complicated chain of chemical reactions inside a cell. In mice, blocking a key link in that chain reduces the number of spines in the front part of the brain, Scott Soderling of Duke University School of Medicine reported. Those mice then exhibited symptoms reminiscent of schizophrenia in people.
It seems that losing spines in the frontal cortex alters nerve cell connections there; with spine shortages, some axons link directly to the dendrite shaft. Bypassing spines, which play a filtering role, can intensify signals sent to the ventral tegmental area, which in turn may send signals that increase production of the chemical messenger dopamine in another brain region, the striatum. “We think that this is actually what is driving the elevated dopamine levels” in disorders such as schizophrenia, Soderling said.
Some antipsychotic drugs (known as neuroleptics) for treating schizophrenia work by blocking sites of dopamine action in the striatum. But such drugs do nothing about the loss of spines that initiated the problem.
“These neuroleptics largely treat these symptoms, but they’re not a cure,” Soderling said. “We think that this is good evidence … for the idea that these drugs are treating a downstream consequence of a primary insult that’s occurring elsewhere in the brain.”
This insight from neuroscience — that antipsychotics treat downstream symptoms, not the problem at its source — may help the search for better treatments.
Soderling suggests that many other mental disorders may have their roots in problems with actin in dendritic spines. Another speaker at the neuroscience meeting, Haruo Kasai of the University of Tokyo, emphasized how fluctuations in the numbers of spines, related to actin activity, could play a role in autism.
Such results from neuroscience should be of great value to fighting mental disorders. But science alone won’t enable the discovery of effective treatments without a broader scope of scientific investigation of mental illness as a global problem. Too much of research to date focuses on too small a portion of the worldwide population. As Saxena noted, more than 90 percent of scientific studies on mental illness are from — and about — high-income countries.
“We are ignoring a very large number of people living in this world,” he said. “And this can be, and is, a real impediment to science. If we don’t know what is happening in the brains of the majority of the people living in this world, can we really advance science in the best possible manner? Can we still say that we know the human brain? And at least my answer would be: No.”
A “three-parent baby” was born in April, the world’s first reported birth from a controversial technique designed to prevent mitochondrial diseases from passing from mother to child.
“As far as we can tell, the baby is normal and free of disease,” says Andrew R. La Barbera, chief scientific officer of the American Society for Reproductive Medicine. “This demonstrates that, in point of fact, the procedure works.”
The baby boy carries DNA not only from his mother and father but also from an egg donor, raising both safety and ethical concerns. In particular, people worry that alterations of the genetic makeup of future generations won’t stop with preventing diseases but could lead to genetically enhanced “designer babies.” Opponents, such as Marcy Darnovsky, executive director of the Center for Genetics and Society in Berkeley, Calif., are also worried that the technique hasn’t been fully tested. “We wish the baby and family well, and hope the baby stays healthy,” Darnovsky says. “But I have a lot of concerns about this child and about future efforts to use these techniques before they’ve been shown to be safe.”
About one in 4,000 children are born with dysfunctional mitochondria. These energy-generating organelles are inherited from the mother and have their own DNA. Mutations in some of the 37 mitochondrial genes can lead to fatal diseases, often affecting energy-hungry organs such as the brain and muscles. Because there is no cure or effective treatment for many mitochondrial diseases, the recent birth has been heralded as a sign of new hope for affected families.
Even if women don’t have mitochondrial diseases themselves, they can pass the diseases to their children if their egg cells contain large numbers of defective mitochondria. The mother of the recent three-parent baby had previously had two children who died of Leigh syndrome, a mitochondrial disease that affects the nervous system and eventually prevents a person from breathing.
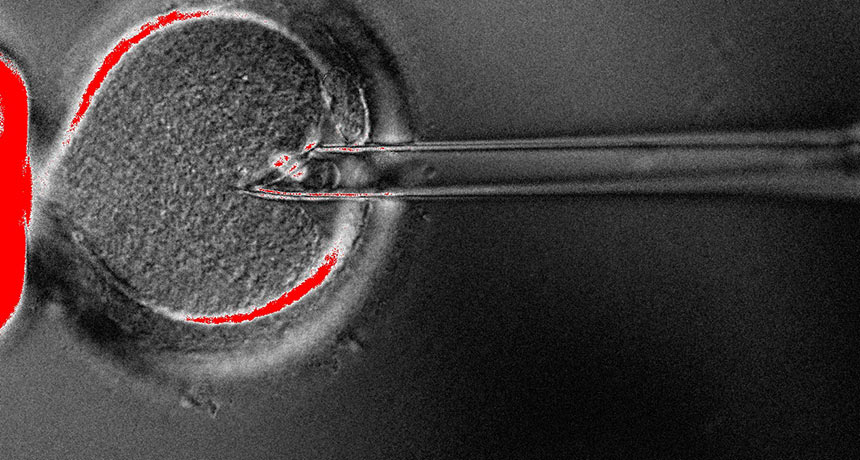
Fertility doctor John Zhang of the New Hope Fertility Center in New York City and colleagues performed what’s called a spindle transfer to put all the chromosomes from the mother’s egg into a donor egg that contained healthy mitochondria but had been emptied of its chromosomes (SN Online: 10/18/16). The egg was then fertilized with sperm and implanted in the mother.
Cell swap A baby boy born in April has DNA from three people. To produce the embryo, researchers transferred the chromosomes from the mother’s egg into a donor egg with healthy mitochondria. The technique is called “spindle transfer” for the cellular structure that segregates the chromosomes.
“It’s very important that they follow up,” to monitor the child’s long-term health, says Shoukhrat Mitalipov, a mitochondrial biologist at Oregon Health & Science University in Portland. Mitalipov pioneered the spindle transfer technique in monkeys (SN: 9/26/09, p. 8). Even a small number of defective mitochondria carried over from the mother’s egg may replicate and cause problems later on, he and other scientists have found (SN: 6/25/16, p. 8; SN Online: 11/30/16).
Zhang reported that just 1.6 percent of the baby boy’s mitochondrial DNA came from his mother (SN Online: 10/19/16). Mitalipov notes, however, that doctors can’t know from sampling a few types of tissue whether other tissues have different levels of mitochondrial carryover. What’s more, levels of mutant mitochondria may change as the child grows.
Mitalipov supports research on the technique but says it should be done in carefully controlled clinical trials. Results of a mouse study published in July suggest that mismatches between the parents’ nuclear DNA and the donor mitochondrial DNA could affect metabolism and aging (SN: 8/6/16, p. 8). Those effects could show up years or decades after birth.
The baby boy born in April is technically not the first three-parent baby. At least two children born in the late 1990s carry mitochondrial DNA from a donor. Those two and 15 other children were born to mothers who had a small amount of cytoplasm — the gelatinous fluid that fills cells and holds mitochondria — from a donor egg injected into their own eggs in an effort to improve results of in vitro fertilization. No major health problems have been reported, but the studies were abandoned because of ethical concerns, lack of funding and the difficulties in obtaining newly required permits.
La Barbera disputes the term “three-parent baby” entirely. “A person’s essence as a human being comes from their nuclear genetic material, not their mitochondrial genetic material,” La Barbera says. Children who are born after mitochondrial transfer procedures have only two parents, he contends.
Zhang drew fire for going to Mexico to perform the procedure. Congress currently bars the U.S. Food and Drug Administration from reviewing applications to make heritable changes in human embryos, which includes the spindle transfer technique. A panel of experts said in February that it is ethical to make three-parent baby boys (SN Online: 2/3/16), a provision that would prevent future generations from inheriting the donor mitochondria. Because mothers pass mitochondria on to their babies but fathers usually do not, technically baby boys born through this technique don’t carry an inheritable modification in their DNA.
Clinics in the United Kingdom can legally perform the procedures, but none have been reported yet. A panel of experts there recommended November 30 that clinical studies could move ahead, so more babies may be born in 2017.
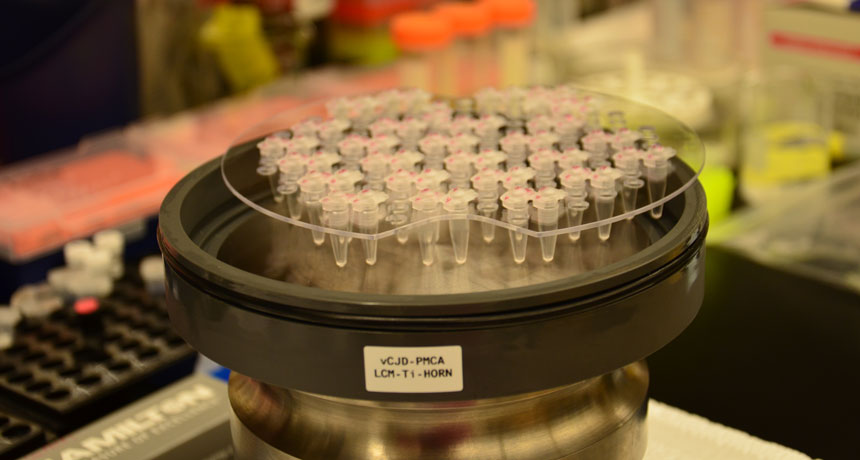
A new blood test can detect even tiny amounts of infectious proteins called prions, two new studies show.
Incurable prion diseases, such as mad cow disease (BSE) in cattle and variant Creutzfeldt-Jakob disease (vCJD) in people, result from a normal brain protein called PrP twisting into a disease-causing “prion” shape that kills nerve cells in the brain. As many as 30,000 people in the United Kingdom may be carriers of prions that cause vCJD, presumably picked up by eating BSE-tainted beef. Health officials worry infected people could unwittingly pass prions to others through blood transfusions. Four such cases have already been recorded. But until now, there has been no way to screen blood for the infectious proteins. In the test, described December 21 in Science Translational Medicine, magnetic nanobeads coated with plasminogen — a protein that prions grab onto — trap prions. Washing the beads gets rid of the rest of the substances in the blood. Researchers then add normal PrP to the beads. If any prions are stuck to the beads, the infectious proteins will convert PrP to the prion form, which will also stick to the beads. After many rounds, the researchers could amplify the signal enough to detect vCJD prions in all the people in the studies known to have the disease.
No healthy people or people with other degenerative brain diseases (including Alzheimer’s and Parkinson’s) in either study had evidence of the infectious proteins in their blood. And only one of 83 people with a sporadic form of Creutzfeld-Jakob disease tested positive. Those results indicate that the test is specific to the vCJD prion form, so a different test is needed to detect the sporadic disease.
In two cases, researchers detected prions in frozen blood samples collected 31 months and 16 months before people developed vCJD symptoms.
Chalk up one more loss for physicists searching for dark matter. Scientists with the XENON100 experiment have largely ruled out another experiment’s controversial claim of detecting dark matter.
XENON100, located in Italy’s Gran Sasso National Laboratory, aims to directly detect particles of dark matter — the unknown substance that scientists believe makes up the bulk of matter in the cosmos (SN: 11/12/16, p. 14).
In their new analysis, published online January 3 at arXiv.org, XENON100 scientists looked for an annual variation in the rate of blips in their detector, a tank filled with 161 kilograms of liquid xenon. Such a signal could be a hallmark of Earth’s motion through a prevailing wind of dark matter particles as the planet makes its yearly jaunt around the sun. Another dark matter experiment at Gran Sasso, DAMA/LIBRA, claims to have found strong evidence of a yearly modulation, but other experiments have failed to replicate the result. Scientists combed over four years of data for events that could be caused by dark matter interacting with electrons in XENON100. The researchers found no evidence of an annual cycle, contradicting DAMA’s claim.
Dark matter optimists can still cling to a caveat, though: DAMA uses a different detection material, composed of sodium iodide crystals rather than xenon. That might explain the difference between the two experiments. Future experiments will attempt to replicate DAMA’s result using the same material.
Dinosaurs might live on today as birds, but they hatched like reptiles. Developing dinos stayed in their eggs three to six months before emerging, far longer than previously suspected, researchers report online January 3 in the Proceedings of the National Academy of Sciences.
With few clues to dinosaurs’ embryonic lives, scientists assumed that young dinosaurs shared modern birds’ swift incubation period, which ranges from 45 to 80 days for eggs in the size range of dino eggs. A reptile egg generally takes about twice as long to hatch as a bird egg of similar size, says lead author Gregory Erickson, a paleobiologist at Florida State University in Tallahassee. But counts of growth lines on the teeth of rare fossilized dinosaur embryos from two species, Protoceratops andrewsi and Hypacrosaurus stebingeri, suggest a longer trajectory like that of reptiles, say Erickson and colleagues at the University of Calgary in Canada and the American Museum of Natural History in New York City. These lines, laid down daily on teeth, can be used like tree rings.
The longer incubation time might have worked against dinosaurs, Erickson says. Guarding a brood of eggs for many months could put parents at risk of attack. And a species hit by environmental catastrophe would have a harder time bouncing back.
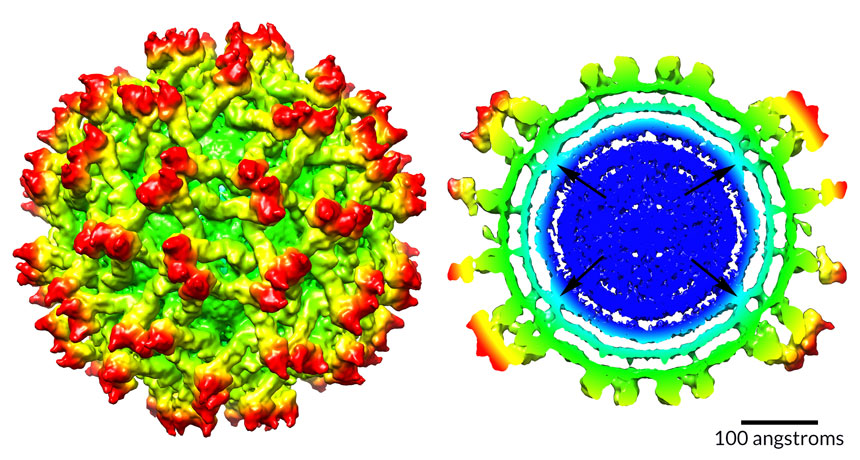
Before an immature Zika virus becomes infectious, it does some major remodeling.
In a fledgling virus particle, the inner protein and RNA core (shown in dark blue above, right) forms bridges to the membrane layer that surrounds it. As the virus matures, the core shuffles around and the bridges melt away (below, right).
It’s the first time scientists have seen such rearrangement in the core of a flavivirus, the group that also includes the viruses that cause dengue, West Nile and yellow fever, says virologist Richard Kuhn of Purdue University in West Lafayette, Ind. Scientists don’t know why the immature Zika virus reshuffles its insides, Kuhn says — perhaps it helps the maturing virus become infectious. But that’s the next big question to answer, he says.
If blocking the reorganization somehow made mature viruses harmless, scientists would have a new clue about preventing Zika infection. Kuhn and colleagues’ map of the immature virus’s structure, published online January 9 in Nature Structural & Molecular Biology, could offer other hints for thwarting Zika.
With a technique called cryo-electron microscopy, the team could see three-headed protein spikes (shown in red) studding the surface like some kind of medieval weapon, and could even distinguish the separate layers of the membrane (aqua) that encloses the core. (The maps are radially colored; colors change as distance from the core increases.) Outside the membrane lie surface proteins called envelope, or E, proteins (green and yellow) that help the virus sneak into cells.
Last year, Kuhn’s team reported the structure of the mature Zika virus (SN: 4/30/16, p. 10). The new work offers another illuminating peek at Zika — a baby picture, of sorts.
Any exercise — even the weekend warrior approach, cramming it all into Saturday and Sunday — is better than none. Compared with inactive adults, those who got the recommended amount of weekly exercise, or even substantially less, had about a one-third lower risk of death during the study period, researchers report online January 9 in JAMA Internal Medicine.
Gary O’Donovan at the University of Leicester in England and colleagues analyzed data from 63,591 people ages 40 and older, surveyed between 1994 and 2012 as part of the Health Survey for England and the Scottish Health Survey. Adults should be getting 150 minutes of moderate activity (such as walking) or 75 minutes of vigorous activity (such as jogging) spread out across the week, according to the U.S. Centers for Disease Control and Prevention and the World Health Organization. Measured against people who did absolutely nothing, active people who worked up a sweat three or more times per week, weekend warriors and even those who moved less (60 minutes per week on average) all reduced their risk of dying early. The observational study can’t say that exercise caused the reduced risk, just that there’s an association.
NASA’s Dawn spacecraft has detected organic compounds on Ceres — the first concrete proof of organics on an object in the asteroid belt between Mars and Jupiter.
This material probably originated on the dwarf planet itself, the researchers report in the Feb. 17 Science. The discovery of organic compounds adds to the growing body of evidence that Ceres may have once had a habitable environment.
“We’ve come to recognize that Ceres has a lot of characteristics that are intriguing for those looking at how life starts,” says Andy Rivkin, a planetary astronomer at the Johns Hopkins University Applied Physics Laboratory in Laurel, Md., who was not involved in the study. The Dawn probe has previously detected salts, ammonia-rich clays and water ice on Ceres, which together indicate hydrothermal activity, says study coauthor Carol Raymond, a planetary scientist at NASA’s Jet Propulsion Laboratory in Pasadena, Calif.
For life to begin, you need elements like carbon, hydrogen, nitrogen and oxygen, as well as a source of energy. Both the hydrothermal activity and the presence of organics point toward Ceres having once had a habitable environment, Raymond says.
“If you have an abundance of those elements and you have an energy source,” she says, “then you’ve created sort of the soup from which life could have formed.” But study coauthor Lucy McFadden, a planetary scientist at NASA’s Goddard Space Flight Center in Greenbelt, Md., stresses that the team has not actually found any signs of life on Ceres.
Evidence of Ceres’ organic material comes from areas near Ernutet crater. Dawn picked up signs of a “fingerprint,” or spectra, consistent with organics. The pattern of wavelengths of light absorbed and reflected from these areas is similar to the pattern seen in hydrocarbons on Earth such as kerite and asphaltite. But without a sample from the surface, the team can’t say definitively what organic material is present or how it formed, says study coauthor Harry McSween, a geologist at the University of Tennessee. The team suspects that the organics formed within Ceres’ interior and were brought to the surface by hydrothermal activity. An alternative idea — that a space rock that crashed into Ceres brought the material — is unlikely, the researchers say, because the concentration of organics is so high. An impact would have mixed organic compounds across the surface, diluting the concentration.
Detecting organics on Ceres also has implications for how life arose on Earth, McSween says. Some researchers think that life was jump-started by asteroids and other space rocks that delivered organic compounds to the planet. Finding such organic matter on Ceres “adds some credence to that idea,” he says.
Big data is everywhere these days and police departments are no exception. As law enforcement agencies are tasked with doing more with less, many are using predictive policing tools. These tools feed various data into algorithms to flag people likely to be involved with future crimes or to predict where crimes will occur.
In the years since Time magazine named predictive policing as one of 2011’s best 50 inventions of the year, its popularity has grown. Twenty U.S. cities, including Chicago, Atlanta, Los Angeles and Seattle are using a predictive policing system, and several more are considering it. But with the uptick in use has come a growing chorus of caution. Community activists, civil rights groups and even some skeptical police chiefs have raised concerns that predictive data approaches may unfairly target some groups of people more than others.
New research by statistician Kristian Lum provides a telling case study. Lum, who leads the policing project at the San Francisco-based Human Rights Data Analysis Group, looked at how the crime-mapping program PredPol would perform if put to use in Oakland, Calif. PredPol, which purports to “eliminate profiling concerns,” takes data on crime type, location and time and feeds it into a machine-learning algorithm. The algorithm, originally based on predicting seismic activity after an earthquake, trains itself with the police crime data and then predicts where future crimes will occur.
Lum was interested in bias in the crime data — not political or racial bias, just the ordinary statistical kind. While this bias knows no color or socioeconomic class, Lum and her HRDAG colleague William Isaac demonstrate that it can lead to policing that unfairly targets minorities and those living in poorer neighborhoods.
By applying the algorithm to 2010 data on drug crime reports for Oakland, the researchers generated a predicted rate of drug crime on a map of the city for every day of 2011. The researchers then compared the data used by the algorithm — drug use documented by the police — with a record of overall drug use, whether recorded or not. This ground-truthing came from taking public health data from the 2011 National Survey on Drug Use and Health and demographic data from the city of Oakland to derive an estimate of drug use for all city residents. In this public health-based map, drug use is widely distributed across the city. In the predicted drug crime map, it is not. Instead, drug use deemed worthy of police attention is concentrated in neighborhoods in West Oakland and along International Boulevard, two predominately low-income and nonwhite areas. Predictive policing approaches are often touted as eliminating concerns about police profiling. But rather than correcting bias, the predictive model exacerbated it, Lum said during a panel on data and crime at the American Association for the Advancement of Science annual meeting in Boston in February. While estimates of drug use are pretty even across race, the algorithm would direct Oakland police to locations that would target black people at roughly twice the rate of whites. A similar disparity emerges when analyzing by income group: Poorer neighborhoods get targeted. And a troubling feedback loop emerges when police are sent to targeted locations. If police find slightly more crime in an area because that’s where they’re concentrating patrols, these crimes become part of the dataset that directs where further patrolling should occur. Bias becomes amplified, hot spots hotter.
There’s nothing wrong with PredPol’s algorithm, Lum notes. Machine learning algorithms learn patterns and structure in data. “The algorithm did exactly what we asked; it learned patterns in the data,” she says. The danger is in thinking that predictive policing will tell you about patterns in the occurrence of crime. It’s really telling you about patterns in police records.
Police aren’t tasked with collecting random samples, nor should they be, says Lum. And that’s all the more reason why departments should be transparent and vigilant about how they use their data. In some ways, PredPol-guided policing isn’t so different from old-fashioned pins on a map.
For her part, Lum would prefer that police stick to these timeworn approaches. With pins on a map, the what, why and where of the data are very clear. The black box of an algorithm, on the other hand, lends undue legitimacy to the police targeting certain locations while simultaneously removing accountability. “There’s a move toward thinking machine learning is our savior,” says Lum. “You hear people say, “A computer can’t be racist.’”
The use of predictive policing may be costly, both literally and figuratively. The software programs can run from $20,000 to up to $100,000 per year for larger cities. It’s harder to put numbers on the human cost of over-policing, but the toll is real. Increased police scrutiny can lead to poor mental health outcomes for residents and undermine relationships between police and the communities they serve. Big data doesn’t help when it’s bad data.